24 KiB
mC Compiler Specification
This document describes the mC compiler as well as the mC language along with some requirements. Like a regular compiler the mC compiler is divided into 3 main parts: front-end, back-end, and a core in-between.
The front-end's task is to validate a given input using syntactic and semantic checks. The syntactic checking is done by the parser, which, on success, generates an abstract syntax tree (AST). This tree data structure is mainly used for semantic checking, although transformations can also be applied to it. Invalid inputs cause errors to be reported. Moving on, the AST is translated to the compiler's intermediate representation (IR) and passed on to the core.
The core provides infrastructure for running analyses and transformations on the IR. These analyses and transformations are commonly used for optimisation. Additional data structures, like the control flow graph (CFG), are utilised for this phase. Next, the (optimised) IR is passed to the back-end.
The back-end translates the platform independent IR code to platform dependent assembly code. An assembler converts this code to object code, which is finally crafted into an executable by the linker. For these last two steps, GCC is used — referred to as back-end compiler in this context.
Adapt project layout, build system, and coding guidelines according to the used programming language's conventions.
mC Language
This section defines mC — a simple, C-like language. The semantics of mC are identical to C unless specified otherwise.
Grammar
The grammar of mC is defined using the following notation:
#starts a single line comment,indicates concatenation|indicates alternation( )indicates grouping[ ]indicates optional parts (0 or 1){ }indicates repetition (1 or more)[ ]and{ }can be combined to build 0 or more repetition" "indicates a terminal string/ /indicates a RegEx
# Primitives
alpha = /[a-zA-Z_]/
alpha_num = /[a-zA-Z0-9_]/
digit = /[0-9]/
identifier = alpha , [ { alpha_num } ]
# Operators
unary_op = "-" | "!"
binary_op = "+" | "-" | "*" | "/"
| "<" | ">" | "<=" | ">="
| "&&" | "||"
| "==" | "!="
# Types
type = "bool" | "int" | "float" | "string"
# Literals
literal = bool_literal
| int_literal
| float_literal
| string_literal
bool_literal = "true" | "false"
int_literal = { digit }
float_literal = { digit } , "." , { digit }
string_literal = /"[^"]*"/
# Declarations / Assignments
declaration = type , [ "[" , int_literal , "]" ] , identifier
assignment = identifier , [ "[" , expression , "]" ] , "=" , expression
# Expressions
expression = literal
| identifier , [ "[" , expression , "]" ]
| call_expr
| unary_op , expression
| expression , binary_op , expression
| "(" , expression , ")"
# Statements
statement = if_stmt
| while_stmt
| ret_stmt
| declaration , ";"
| assignment , ";"
| expression , ";"
| compound_stmt
if_stmt = "if" , "(" , expression , ")" , statement , [ "else" , statement ]
while_stmt = "while" , "(" , expression , ")" , statement
ret_stmt = "return" , [ expression ] , ";"
compound_stmt = "{" , [ { statement } ] , "}"
# Function Definitions / Calls
function_def = ( "void" | type ) , identifier , "(" , [ parameters ] , ")" , compound_stmt
parameters = declaration , [ { "," , declaration } ]
call_expr = identifier , "(" , [ arguments ] , ")"
arguments = expression , [ { "," expression } ]
# Program (Entry Point)
program = [ { function_def } ]
Comments
mC supports only C-style comments, starting with /* and ending with */.
Like in C, they can span across multiple lines.
Comments are discarded by the parser; however, line breaks are taken into account for line numbering.
Size Limitations
long and double are used in the compiler to store mC's int and float literals, respectively.
It is assumed that both types are big and precise enough to store the corresponding literal.
Furthermore, it is assumed that arrays and strings are at most LONG_MAX elements long.
Special Semantics
Boolean
bool is considered a first-class citizen, distinct from int.
The operators !, &&, and || can only be used with Booleans.
Short-circuit evaluation is not supported.
An expression used as a condition (for if or while) is expected to be of type bool.
Strings
Strings are immutable and do not support any operation (e.g. concatenation). Like comments, strings can span across multiple lines. Whitespaces (i.e. newlines, tabs, spaces) are part of the string. Escape sequences are not supported.
The sole purpose of strings in mC is to be used with the built-in print function (see below).
Arrays
Only one dimensional arrays with static size are supported. The size must be stated during declaration and is part of the type. The following statement declares an array of integers with 42 elements.
int[42] my_array;
We do not support any operations on whole arrays. For example, the following code is invalid:
int[10] a;
int[10] b;
int[10] c;
c = a + b; /* not supported */
This needs to be rewritten as a loop in order to work:
int i;
i = 0;
while (i < 10) {
c[i] = a[i] + b[i];
i = i + 1;
}
Even further, one cannot assign to a variable of array type.
c = a; /* not supported, even though both are of type int[10] */
Call by Value / Call by Reference
bool, int, and float are passed by value.
For arrays and strings a pointer is passed by value (similar to C).
Modifications made to an array inside a function are visible outside the function.
void foo(int[5] arr) {
arr[2] = 42;
}
int main() {
int[5] arr;
foo(arr);
print_int(arr[2]); /* outputs 42 */
return 0;
}
While strings can be re-assigned (in contrast to arrays), this is not visible outside the function call.
void foo(string s) {
s = "foo";
}
int main() {
string s;
s = "bar";
foo(s);
print(s); /* outputs bar */
return 0;
}
Type Conversion
There are no type conversion, neither implicit nor explicit.
Entry Point
The top-level grammar rule is program which consists of 0 or more function definitions.
While the parser happily accepts empty source files, a semantic check enforces the presence of a function named main.
This function takes no arguments and returns an int.
On success, an mC program's main function returns 0.
Declaration, Definition, and Initialization
declaration is used to declare variables which can then be initialised with assignment.
Splitting declaration and initialisation simplifies the creation of symbol tables.
Contrary to C, it is possible to call a function before it has been declared (in case of mC defined). Forward declarations are therefore not supported.
Empty Parameter List
In mC, an empty parameter list is always written as ().
Dangling Else
A dangling else belongs to the innermost if.
The following mC code snippets are semantically equivalent:
if (c1) | if (c1) {
if (c2) | if (c2) {
f2(); | f2();
else | } else {
f3(); | f3();
| }
| }
Built-in Functions
The following built-in functions are provided by the compiler for I/O operations:
void print(string)outputs the given string tostdoutvoid print_nl()outputs the new-line character (\n) tostdoutvoid print_int(int)outputs the given integer tostdoutvoid print_float(float)outputs the given float tostdoutint read_int()reads an integer fromstdinfloat read_float()reads a float fromstdin
mC Compiler
The mC compiler is implemented as a library. It can be used either programmatically or via the provided command-line applications (see below).
The focus lies on a clean and modular implementation as well as a straightforward architecture, rather than raw performance. For example, each semantic check may traverse the AST in isolation.
The compiler guarantees the following:
- All functions are thread-safe.
- Functions do not interact directly with
stdin,stdout, orstderr. - No function terminates the application on correct usage (or replaces the running process using
exec). - No memory is leaked — even in error cases.
Note for C: Prefix symbols with mcc_ due to the lack of namespaces.
Logging
Logging infrastructure may be present; however, all log (and debug) output is disabled by default.
The log level can be set with the environment variable MCC_LOG_LEVEL.
0 = no logging
1 = normal logging (info)
2 = verbose logging (debug)
The output destination can be set with MCC_LOG_FILE and defaults to stderr.
Log messages do not overlap on multi-threaded execution.
Parser
The parser reads the given input and, if it conforms syntactically to an mC program, constructs the corresponding AST. An invalid input is rejected, resulting in a meaningful error message. For instance:
foo.mc:3:8: error: unexpected '{', expected ‘(’
It is recommended to closely follow the error message format of other compilers. This allows for better IDE integration.
Displaying the offending source code along with the error message is helpful, but not required.
Parsing may stop on the first error. Error recovery is optional. Pay attention to operator precedence.
Note that partial mC programs, like an expression or statement, are not valid inputs to the main parse function. The library may provide additional functions for parsing single expressions or statements.
Abstract Syntax Tree
The AST data structure itself is not specified.
Consider using the visitor pattern for tree traversals.
Given this example input:
int fib(int n)
{
if (n < 2) return n;
return fib(n - 1) + fib(n - 2);
}
The visualisation of the AST for the fib function could look like this:
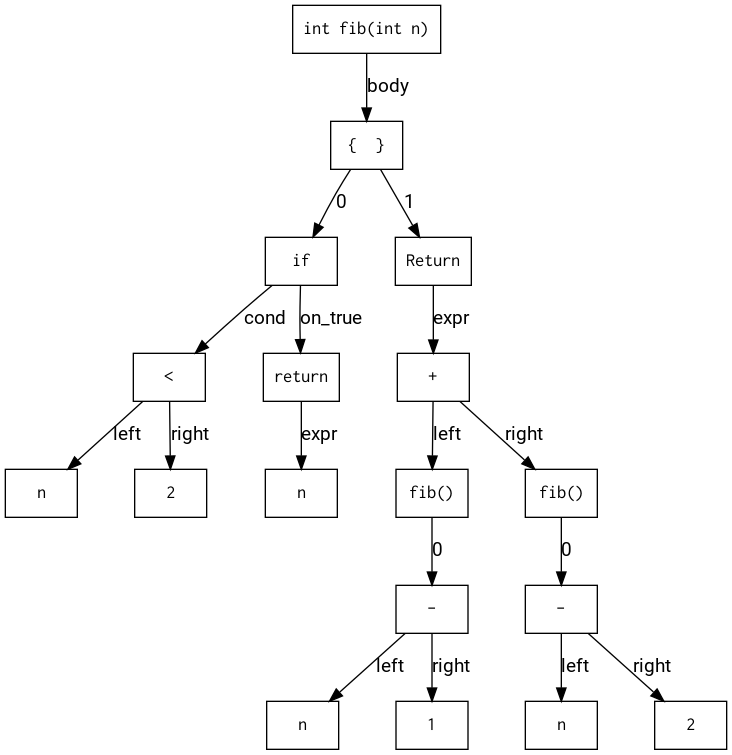
Semantic Checks
As the parser only does syntactic checking, additional semantic checks are implemented:
- Checking for uses of undeclared variables
- Checking for multiple declarations of variables with the same name in the same scope
- Checking for multiple definitions of functions with the same name
- Checking for calls to unknown functions
- Checking for presence of
mainand correct signature - Checking that all execution paths of a non-void function return a value
- Type checking (remember, neither implicit nor explicit type conversions)
- Includes checking operations on arrays (including array size)
- Includes checking arguments and return types for call expressions
Semantic checking may stop on the first error encountered.
In addition to the AST, symbol tables are created and used for semantic checking. Be sure to correctly model shadowing.
Intermediate Representation
As IR, a low-level three-address code (TAC) is used. The instruction set of this IR is not specified.
The compiler's core is independent from the front- and back-end.
Hint: Handle arguments and return values for function calls via an imaginary stack using dedicated push and pop instructions.
Have a look at the calling convention used for assembly code generation.
Control Flow Graph (CFG)
A control flow graph data structure consisting of edges and basic blocks (containing IR instructions) is present. For each function in a given IR program, a corresponding CFG can be obtained.
The CFG is commonly used by analyses for extracting structural information crucial for transformation steps.
Providing a visitor mechanism for CFGs is optional, yet recommended.
Like the AST, CFGs can be printed using the DOT format. The example below is taken from Marc Moreno Maza.
Given this example IR:
s = 0
i = 0
n = 10
L1: t1 = a - b
ifz t1 goto L2
t2 = i * 4
s = s + t2
goto L3
L2: s = s + i
L3: i = i + 1
t3 = n - i
ifnz t3 goto L1
t4 = a - b
The visualisation of the corresponding CFG could look like this:
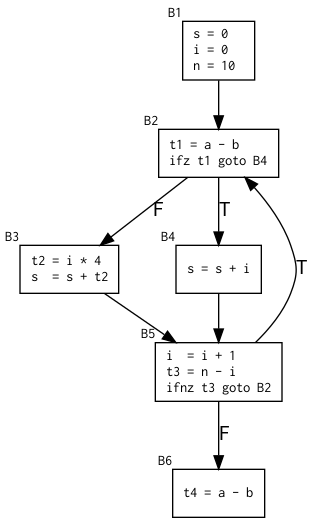
Assembly Code Generation
The mC compiler targets x86 and uses GCC as back-end compiler.
On an x86_64 system, GCC multi-lib support must be available and the flag -m32 is passed to the compiler.
The code generated by the back-end is compiled with the GNU Assembler (by GCC). Pay special attention to floating point and integer handling.
Use cdecl calling convention. It is paramount to correctly implement the calling convention, otherwise the stack may get corrupted during function calls and returns. Note that all function calls (including built-ins) use the same calling convention — do not needlessly introduce special cases.
Hint: There is a .float assembler directive.
Hint: If you are not familiar with x86 assembly, pass small C snippets to GCC and look at the generated assembly code (using -S).
Optimisations, mitigations, and other unnecessary features (e.g. dwarf symbols, unwind tables) should be disabled.
There are also flags like -fverbose-asm which add additional annotations to the output.
Applications
Apart from the main compiler executable mcc, additional auxiliary executables are provided.
These executables aid the development process and are used for evaluation.
Do not omit details in the output (e.g. do not simplifying the AST).
The applications are specified by their usage information.
Composing them with other command-line tools, like dot, is a core feature.
All applications exit with code EXIT_SUCCESS iff they succeeded in their operation.
Errors are written to stderr.
mcc
This is the main compiler executable, sometimes referred to as driver.
usage: mcc [OPTIONS] <file>
The mC compiler. It takes an mC input file and produces an executable.
Errors are reported on invalid inputs.
Use '-' as input file to read from stdin.
OPTIONS:
-h, --help display this help message
-q, --quiet suppress error output
-o, --output <out-file> write the output to <out-file> (defaults to 'a.out')
Environment Variables:
MCC_BACKEND override the back-end compiler (defaults to 'gcc')
mc_ast_to_dot
usage: mc_ast_to_dot [OPTIONS] <file>
Utility for printing an abstract syntax tree in the DOT format. The output
can be visualised using Graphviz. Errors are reported on invalid inputs.
Use '-' as input file to read from stdin.
OPTIONS:
-h, --help display this help message
-o, --output <out-file> write the output to <out-file> (defaults to stdout)
mc_symbol_table
usage: mc_symbol_table [OPTIONS] <file>
Utility for displaying the generated symbol tables. Errors are reported on
invalid inputs.
Use '-' as input file to read from stdin.
OPTIONS:
-h, --help display this help message
-o, --output <out-file> write the output to <out-file> (defaults to stdout)
mc_ir
usage: mc_ir [OPTIONS] <file>
Utility for viewing the generated intermediate representation. Errors are
reported on invalid inputs.
Use '-' as input file to read from stdin.
OPTIONS:
-h, --help display this help message
-o, --output <out-file> write the output to <out-file> (defaults to stdout)
mc_cfg_to_dot
usage: mc_cfg_to_dot [OPTIONS] <file>
Utility for printing a control flow graph in the DOT format. The output
can be visualised using graphviz. Errors are reported on invalid inputs.
Use '-' as input file to read from stdin.
OPTIONS:
-h, --help display this help message
-o, --output <out-file> write the output to <out-file> (defaults to stdout)
-f, --function <name> print the CFG of the given function (defaults to 'main')
mc_asm
usage: mc_asm [OPTIONS] <file>
Utility for printing the generated assembly code. Errors are reported on
invalid inputs.
Use '-' as input file to read from stdin.
OPTIONS:
-h, --help display this help message
-o, --output <out-file> write the output to <out-file> (defaults to stdout)
Project Structure
The following directory layout is used.
mcc/ # This node represents the root of the repository.
├── app/ # Each C file in this directory corresponds to one executable.
│ ├── mc_ast_to_dot.c
│ ├── mcc.c
│ └── …
├── docs/ # Additional documentation goes here.
│ └── …
├── include/ # All public headers live here, note the `mcc` subdirectory.
│ └── mcc/
│ ├── ast.h
│ ├── ast_print.h
│ ├── ast_visit.h
│ ├── parser.h
│ └── …
├── src/ # The actual implementation; may also contain private headers and so on.
│ ├── ast.c
│ ├── ast_print.c
│ ├── ast_visit.c
│ ├── parser.y
│ ├── scanner.l
│ └── …
├── test/
│ ├── integration/ # Example inputs for integration testing.
│ │ ├── fib/
│ │ │ ├── fib.mc
│ │ │ ├── fib.stdin.txt
│ │ │ └── fib.stdout.txt
│ │ └── …
│ └── unit/ # Unit tests, typically one file per unit.
│ ├── parser_test.c
│ └── …
├── vendor/ # Third-party libraries and tools go here.
│ └── …
└── README.md
The README is kept short and clean with the following sections:
- Prerequisites
- Build instructions
- Known issues
src contains the implementation of the library, while include defines its API.
Each application (C file inside app) uses the library via the provided interface.
They mainly contain argument parsing and combine the functionality offered by the API to achieve their tasks.
The repository does not contain or track generated files. All generated files are placed inside a build directory (i.e. out-of-source build).
Known Issues
At any point in time, the README contains a list of unfixed, known issues.
Each entry is kept short and concise including a justification.
Complex issues may reference a dedicated document inside docs elaborating it in greater detail.
Testing
Crucial or complicated logic should be tested adequately.
The project infrastructure provides a simple way to run all unit and integration tests. See the getting started code-base for example.
Similarly, a way to run unit tests using valgrind is provided.
Dependencies
The prerequisites section of the README enumerates all dependencies. The implementation should not have any dependencies apart from the standard library, system libraries (POSIX), a testing framework, and a lexer / parser generator.
If a dependency is not available via the evaluation system's package manager, it needs to be automatically built and used by the build system. It is recommended to vendor such dependencies rather than downloading them during build time.
Coding Guidelines
Architectural design and readability of your code will be judged.
- Don't be a git — use Git!
- Files are UTF-8 encoded and use Unix line-endings (
\n). - Files contain one newline at the end.
- Lines do not contain trailing whitespaces.
- Your code does not trigger warnings, justify them if otherwise.
- Do not waste time or space (this includes memory leaks).
- Check for leaks using
valgrind, especially in error cases. - Keep design and development principles in mind, especially KISS and DRY.
- Always state the source of non-original content.
- Use persistent links when possible.
- Ideas and inspirations should be referenced too.
Credit where credit is due.
C/C++
- While not required, it is highly recommended to use a formatting tool, like ClangFormat. A configuration file is provided in the getting started code-base; however, you are free to rule your own.
- Consider enabling address and memory sanitizers.
- Lines should not exceed 120 columns.
- The nesting depth of control statements should not exceed 4.
- Move inner code to dedicated functions or macros.
- Avoid using conditional and loop statements inside
case.
- Use comments where necessary.
- Code should be readable and tell what is happening.
- A comment should tell you why something is happening, or what to look out for.
- An overview at the beginning of a module header is welcome.
- Use the following order for includes (separated by an empty line):
- Corresponding header (
ast.c→ast.h) - System headers
- Other library headers
- Public headers of the same project
- Private headers of the same project
- Corresponding header (
- The structure of a source file should be similar to its corresponding header file.
- Separators can be helpful, but they should not distract the reader.
- Keep public header files free from implementation details, this also applies to the overview comment.
- Use assertions to verify preconditions.
- Ensure the correct usage of library functions, remember to always check return codes.
- Prefer bound-checking functions, like
snprintf, over their non-bound-checking variant.
Also, keep the following in mind, taken from Linux Kernel Coding Style:
Functions should be short and sweet, and do just one thing. They should fit on one or two screenfuls of text (the ISO/ANSI screen size is 80x24, as we all know), and do one thing and do that well.
The maximum length of a function is inversely proportional to the complexity and indentation level of that function. So, if you have a conceptually simple function that is just one long (but simple) case-statement, where you have to do lots of small things for a lot of different cases, it's OK to have a longer function.
However, if you have a complex function, and you suspect that a less-than-gifted first-year high-school student might not even understand what the function is all about, you should adhere to the maximum limits all the more closely. Use helper functions with descriptive names (you can ask the compiler to in-line them if you think it's performance-critical, and it will probably do a better job of it than you would have done).
Another measure of the function is the number of local variables. They shouldn't exceed 5–10, or you’re doing something wrong. Re-think the function, and split it into smaller pieces. A human brain can generally easily keep track of about 7 different things, anything more and it gets confused. You know you’re brilliant, but maybe you'd like to understand what you did 2 weeks from now.